Flask-Blogging¶
Flask-Blogging is a Flask extension for adding blog support to your site. It provides a flexible mechanism to store the data in the database of your choice. It is meant to work with the authentication provided by packages such as Flask-Login or Flask-Security.
The philosophy behind this extension is to provide a lean app based on markdown to provide blog support to your existing web application. This is contrary to some other packages such as that are just blogs. If you already have a web app and you need to have a blog to communicate with your user or to promote your site through content based marketing.
Out of the box Flask-Blogging has support for the following:
- Bootstrap based site
- Markdown based blog editor
- Models to store blog
- Authentication of User’s choice
- Sitemap, ATOM support
- Disqus support for comments
- Google analytics for usage tracking
- Well documented, tested, and extensible design
Quick Start Example¶
from flask import Flask, render_template_string, redirect
from sqlalchemy import create_engine
from flask.ext.login import UserMixin, LoginManager, \
login_user, logout_user
from flask_blogging import SQLAStorage, BloggingEngine
app = Flask(__name__)
app.config["SECRET_KEY"] = "secret" # for WTF-forms and login
# extensions
engine = create_engine('sqlite:////tmp/blog.db')
sql_storage = SQLAStorage(engine)
blog_engine = BloggingEngine(app, sql_storage, url_prefix="/blog")
login_manager = LoginManager(app)
# user class for providing authentication
class User(UserMixin):
def __init__(self, user_id):
self.id = user_id
def get_name(self):
return "Paul Dirac" # typically the user's name
@login_manager.user_loader
@blog_engine.user_loader
def load_user(user_id):
return User(user_id)
index_template = """
<!DOCTYPE html>
<html>
<head> </head>
<body>
{% if current_user.is_authenticated() %}
<a href="/logout/">Logout</a>
{% else %}
<a href="/login/">Login</a>
{% endif %}
  <a href="/blog/">Blog</a>
  <a href="/blog/sitemap.xml">Sitemap</a>
  <a href="/blog/feeds/all.atom.xml">ATOM</a>
</body>
</html>
"""
@app.route("/")
def index():
return render_template_string(index_template)
@app.route("/login/")
def login():
user = User("testuser")
login_user(user)
return redirect("/blog")
@app.route("/logout/")
def logout():
logout_user()
return redirect("/")
if __name__ == "__main__":
app.run(debug=True, port=8000, use_reloader=True)
The key components required to get the blog hooked is explained below.
Configuring your Application¶
The BloggingEngine class is the gateway to configure blogging support to your web app. You should create the BloggingEngine instance like this:
blogging_engine = BloggingEngine()
You also need to pick the storage for blog. That can be done as:
from sqlalchemy import create_engine
engine = create_engine("sqlite:////tmp/sqlite.db")
storage = SQLAStorage(engine)
Once you have created the blogging engine and the storage, you can connect with your app using the init_app method as shown below:
blogging_engine.init_app(app, storage)
Flask-Blogging lets the developer pick the authentication that is suitable, and hence requires her to provide a way to load user information. You will need to provide a BloggingEngine.user_loader callback. This callback is used to load the user from the user_id that is stored for each blog post. Just as in Flask-Login, it should take the unicode user_id of a user, and return the corresponding user object. For example:
@blogging_engine.user_loader
def load_user(userid):
return User.get(userid)
For the blog to have a readable display name, the User class must
implement either the get_name method or the __str__ method.
The BloggingEngine accepts an optional config dict argument which is passed to all
the views. The keys that are currently supported include:
| SITENAME | The name of the blog to be used as the brand name (default “Flask-Blogging”) |
| SITEURL | The url of the site. |
| RENDER_TEXT | Boolean value to specify if the raw text should be
rendered or not. (default True) |
| DISQUS_SITENAME | Disqus sitename for comments (default None) |
| GOOGLE_ANALYTICS | Google analytics code for usage tracking
(default None) |
The BloggingEngine accepts an optional extensions argument. This is a list
of Markdown extensions objects to be used during the markdown processing step.
Blog Views¶
There are various views that are exposed through Flask-Blogging. If the url_prefix
argument in the BloggingEngine is /blog, then the URL for the various views are:
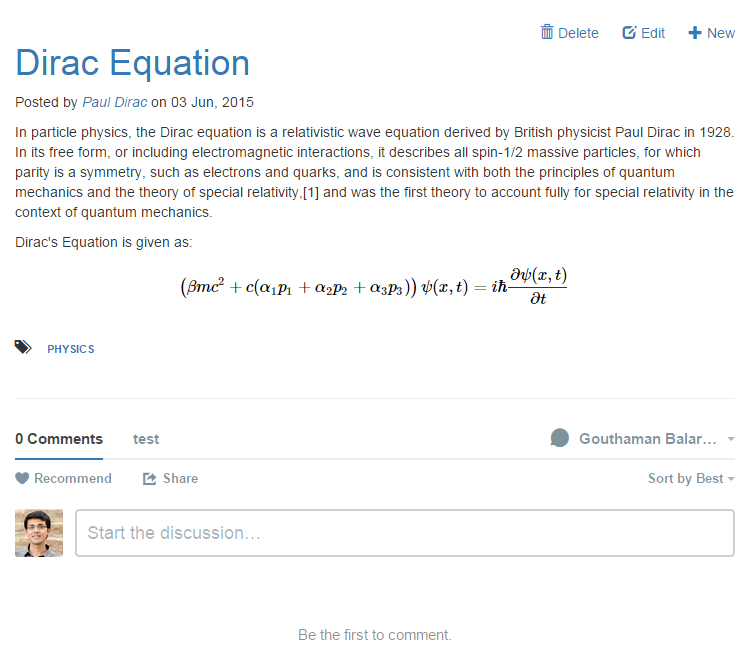
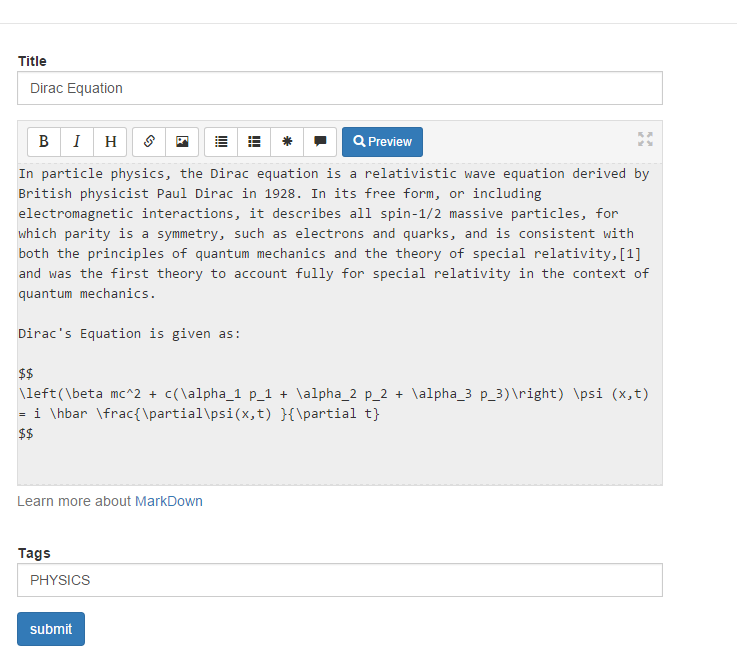
/blog/(GET): The index blog posts with the first page of articles./blog/page/<post_id>/<optional slug>/(GET): The blog post corresponding to thepost_idis retrieved./blog/tag/<tag_name/(GET): The list of blog posts corresponding totag_nameis returned./blog/author/<user_id>/(GET): The list of blog posts written by the authoruser_idis returned./blog/editor/(GET, POST): The blog editor is shown. This view needs authentication./blog/delete/<post_id>/(POST): The blog post given bypost_idis deleted. This view needs authentication./blog/sitemap.xml(GET): The sitemap with a link to all the posts is returned.
The view can be easily customised by the user by overriding with their own templates. The template pages that need to be customized are:
blog/index.html: The blog index page used to serve index of posts, posts by tag, and posts by authorblog/editor.html: The blog editor page.blog/page.html: The page that shows the given article.blog/sitemap.xml: The sitemap for the blog posts.
API Documentation¶
Module contents¶
Flask-Blogging is a Flask extension to add blog support to your web application. This extension uses Markdown to store and then render the webpage.
Author: Gouthaman Balaraman
Date: June 1, 2015
Submodules¶
flask_blogging.engine module¶
The BloggingEngine module.
-
class
flask_blogging.engine.BloggingEngine(app=None, storage=None, url_prefix=None, post_processor=None, config=None, extensions=None)¶ Bases:
objectThe BloggingEngine is the class for initializing the blog support for your web app. Here is an example usage:
from flask import Flask from flask.ext.blogging import BloggingEngine, SQLAStorage from sqlalchemy import create_engine app = Flask(__name__) db_engine = create_engine("sqlite:////tmp/sqlite.db") storage = SQLAStorage(db_engine) blog_engine = BloggingEngine(app, storage)
-
__init__(app=None, storage=None, url_prefix=None, post_processor=None, config=None, extensions=None)¶ Parameters: - app (object) – Optional app to use
- storage (object) – The blog storage instance that implements the
Storageclass interface. - url_prefix (str) – (optional) The prefix for the URL of blog posts (default
None) - post_processor (object) – (optional) The post processor object. If none provided, the default is used.
- config (dict) – (optional) A dictionary of config values. See docs for the keys that can be specified.
- extensions (list) – A list of markdown extensions to add to post processing step.
Returns:
-
init_app(app, storage)¶ Initialize the engine.
Parameters: - app – The app to use
- storage – The blog storage instance that implements the
Storageclass interface.
-
user_loader(callback)¶ The decorator for loading the user.
Parameters: callback – The callback function that can load a user given a unicode user_id.Returns: The callback function
-
flask_blogging.processor module¶
-
class
flask_blogging.processor.PostProcessor¶ Bases:
object-
classmethod
all_extensions()¶
-
classmethod
construct_url(post)¶
-
static
create_slug(title)¶
-
classmethod
custom_process(post)¶ Override this method to add additional processes. The result is that the
postdict is modified or enhanced with newer key value pairs.Parameters: post (dict) – The post data with values for keys such as title, text, tags etc.
-
classmethod
process(post, render=True)¶ This method takes the post data and renders it :param post: :param render: :return:
-
classmethod
render_text(post)¶
-
classmethod
set_custom_extensions(extensions)¶
-
classmethod
flask_blogging.sqlastorage module¶
-
class
flask_blogging.sqlastorage.SQLAStorage(engine, table_prefix='')¶ Bases:
flask_blogging.storage.StorageThe
SQLAStorageimplements the interface specified by theStorageclass. This class uses SQLAlchemy to implement storage and retrieval of data from any of the databases supported by SQLAlchemy. This-
__init__(engine, table_prefix='')¶ The constructor for the
SQLAStorageclass.Parameters: - engine (object) – The
SQLAlchemyengine instance created by callingcreate_engine. One can also use Flask-SQLAlchemy, and pass the engine property. - table_prefix (str) – (Optional) Prefix to use for the tables created (default
"").
- engine (object) – The
-
count_posts(tag=None, user_id=None, include_draft=False)¶ Returns the total number of posts for the give filter
Parameters: - tag (str) – Filter by a specific tag
- user_id (str) – Filter by a specific user
- include_draft (bool) – Whether to include posts marked as draft or not
Returns: The number of posts for the given filter.
-
delete_post(post_id)¶ Delete the post defined by
post_idParameters: post_id (int) – The identifier corresponding to a post Returns: Returns True if the post was successfully deleted and False otherwise.
-
get_post_by_id(post_id)¶ Fetch the blog post given by
post_idParameters: post_id (int) – The post identifier for the blog post Returns: If the post_idis valid, the post data is retrieved, else returnsNone.
-
get_posts(count=10, offset=0, recent=True, tag=None, user_id=None, include_draft=False)¶ Get posts given by filter criteria
Parameters: - count (int) – The number of posts to retrieve (default 10)
- offset (int) – The number of posts to offset (default 0)
- recent (bool) – Order by recent posts or not
- tag (str) – Filter by a specific tag
- user_id (str) – Filter by a specific user
- include_draft (bool) – Whether to include posts marked as draft or not
Returns: A list of posts, with each element a dict containing values for the following keys: (title, text, draft post_date, last_modified_date). If count is
None, then all the posts are returned.
-
save_post(title, text, user_id, tags, draft=False, post_id=None)¶ Persist the blog post data. If
post_idisNoneorpost_idis invalid, the post must be inserted into the storage. Ifpost_idis a valid id, then the data must be updated.Parameters: - title (str) – The title of the blog post
- text (str) – The text of the blog post
- user_id (str) – The user identifier
- tags (list) – A list of tags
- draft (bool) – (Optional) If the post is a draft of if needs to be published. (default
False) - post_id (int) – (Optional) The post identifier. This should be
Nonefor an insert call, and a valid value for update. (defaultNone)
Returns: The post_id value, in case of a successful insert or update. Return
Noneif there were errors.
-
flask_blogging.storage module¶
-
class
flask_blogging.storage.Storage¶ Bases:
object-
count_posts(tag=None, user_id=None, include_draft=False)¶ Returns the total number of posts for the give filter
Parameters: - tag (str) – Filter by a specific tag
- user_id (str) – Filter by a specific user
- include_draft (bool) – Whether to include posts marked as draft or not
Returns: The number of posts for the given filter.
-
delete_post(post_id)¶ Delete the post defined by
post_idParameters: post_id (int) – The identifier corresponding to a post Returns: Returns True if the post was successfully deleted and False otherwise.
-
get_post_by_id(post_id)¶ Fetch the blog post given by
post_idParameters: post_id (int) – The post identifier for the blog post Returns: If the post_idis valid, the post data is retrieved, else returnsNone.
-
get_posts(count=10, offset=0, recent=True, tag=None, user_id=None, include_draft=False)¶ Get posts given by filter criteria
Parameters: - count (int) – The number of posts to retrieve (default 10). If count is
None, all posts are returned. - offset (int) – The number of posts to offset (default 0)
- recent (bool) – Order by recent posts or not
- tag (str) – Filter by a specific tag
- user_id (str) – Filter by a specific user
- include_draft (bool) – Whether to include posts marked as draft or not
Returns: A list of posts, with each element a dict containing values for the following keys: (title, text, draft post_date, last_modified_date). If count is
None, then all the posts are returned.- count (int) – The number of posts to retrieve (default 10). If count is
-
save_post(title, text, user_id, tags, draft=False, post_id=None)¶ Persist the blog post data. If
post_idisNoneorpost_idis invalid, the post must be inserted into the storage. Ifpost_idis a valid id, then the data must be updated.Parameters: - title (str) – The title of the blog post
- text (str) – The text of the blog post
- user_id (str) – The user identifier
- tags (list) – A list of tags
- draft (bool) – If the post is a draft of if needs to be published.
- post_id (int) – The post identifier. This should be
Nonefor an insert call, and a valid value for update.
Returns: The post_id value, in case of a successful insert or update. Return
Noneif there were errors.
-
flask_blogging.views module¶
-
flask_blogging.views.delete(*args, **kwargs)¶
-
flask_blogging.views.editor(*args, **kwargs)¶
-
flask_blogging.views.index(count, page)¶ Serves the page with a list of blog posts
Parameters: - count –
- offset –
Returns:
-
flask_blogging.views.page_by_id(post_id, slug)¶
-
flask_blogging.views.posts_by_tag(tag, count, page)¶
-
flask_blogging.views.recent_feed()¶
-
flask_blogging.views.sitemap()¶
flask_blogging.forms module¶
-
class
flask_blogging.forms.BlogEditor(formdata=<class flask_wtf.form._Auto>, obj=None, prefix='', csrf_context=None, secret_key=None, csrf_enabled=None, *args, **kwargs)¶ -
draft= <UnboundField(BooleanField, ('draft',), {'default': False})>¶
-
submit= <UnboundField(SubmitField, ('submit',), {})>¶
-
text= <UnboundField(TextAreaField, ('text',), {'validators': [<wtforms.validators.DataRequired object at 0x7f93f2d2fcd0>]})>¶
-
title= <UnboundField(StringField, ('title',), {'validators': [<wtforms.validators.DataRequired object at 0x7f93f2d2fc50>]})>¶
-
